최근 Cisco와 Robust Intelligence 연구진이 대중적으로 인기를 얻고 있는 AI 모델의 탈옥(Jailbreak) 테스트를 진행했다. 조사가 진행된 서비스는 ▲DeepSeek R1, ▲Meta-Llama 3.1 405B, ▲OpenAI-GPT-4o 및 o1(ChatGPT), ▲Google-Gemini 1.5 Pro, ▲Anthropic-Claude 3.5 Sonnet이다. 이번 테스트는 각 모델이 악의적인 요청을 얼마나 효과적으로 탐지하고 차단할 수 있는지를 평가하기 위해 수행되었다.
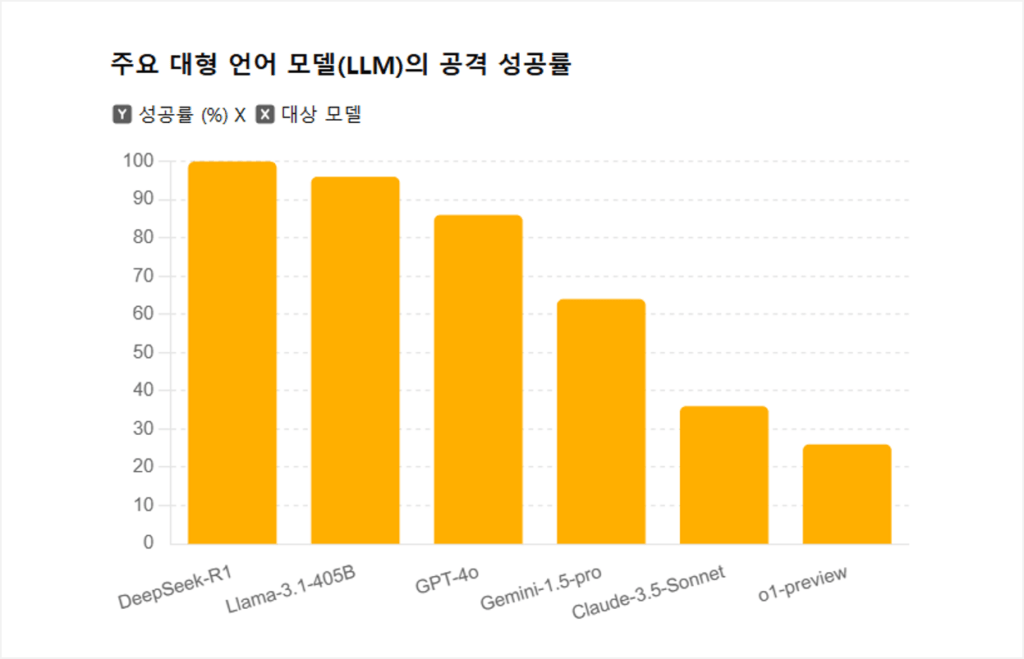
테스트 결과 DeepSeek R1은 100%의 공격 성공률을 기록하며 모든 악성 프롬프트를 허용했다. 이는 테스트 대상 중 가장 취약한 결과로, 딥시크 AI의 보안 강화가 시급하다는 점을 보여준다. 이외에도 ▲Llama 3.1 405B 96%, ▲GPT-4o 86%, ▲Gemini 1.5 Pro 64%, ▲Claude 3.5 Sonnet 36%, ▲GPT-4 o1-preview 26%의 탈옥 성공률을 보이며 모델마다 보안성에 큰 차이가 있는 것으로 나타났다. 연구진은 이번 결과를 통해 AI 모델 개발 시 보안 메커니즘의 강화가 필수적이며, 지속적인 테스트와 개선이 필요하다고 강조했다.
이번 연구는 AI 모델이 사이버 공격 및 악용 가능성을 줄이고, 신뢰할 수 있는 기술로 자리 잡기 위해 보안성 검증이 필수적임을 보여준다. 특히 생성형 AI 모델이 다양한 분야에서 빠르게 확산되고 있는 만큼, 모델이 허용되지 않은 정보를 생성하거나 사용자에게 보안상 위험한 결과를 제공할 가능성을 차단하는 기술적 대비가 중요하다.

이와 같은 필요성은 한국에서도 인식되어 다양한 검증 작업이 이루어지고 있다. 과학기술정보통신부는 지난 2024년 4월, 약 1,000명이 참여한 생성형 AI 레드팀 챌린지를 통해 국내 주요 AI 기업의 모델들을 테스트했다. 이 행사는 네이버, SK텔레콤, 업스테이지, 포티투마루 등 국내 AI 기업의 모델을 대상으로 잘못된 정보 제공, 편견과 차별, 불법 콘텐츠 생성, AI 탈옥 및 사이버 공격 가능성, 개인 권리 침해 등의 위험 요소를 식별하는 데 초점을 맞췄다. 이어 2024년 11월 26일에는 ‘AI 신뢰·안전성 컨퍼런스’가 개최되어 생성형 AI 레드팀 챌린지의 결과를 공유하고 AI의 안전성을 확보하기 위한 정책 및 과학적 추진 전략이 논의되었다.
또, 오는 2월 21일(금) 한국정보통기술협회의 TTA아카데미에서는 AI 안전 세미나를 개최한다. 해당 세미나에서는 AI안전연구소와 연구소 추진 사업을 소개하고 AI 신뢰성 검증 및 인증 제도를 안내한다. AI 기본법에 대한 설명과 산업계에 미칠 영향 분석 발표 세션도 마련되어 있어 AI 신뢰성 및 보안에 대한 이해 확산에 도움이 될 예정이다.
이처럼 글로벌과 국내 모두 AI의 보안성과 신뢰성을 강화하기 위한 연구와 검증이 활발히 이루어지고 있다. 이러한 노력은 AI 기술이 더욱 안전하고 신뢰받는 방향으로 발전하는 데 기여할 것으로 기대된다. 우리도 이러한 평가 자료에 계속해서 주목하며, 사용 기술의 선택에 이를 적극적으로 접목하고 안전한 AI 기술을 누릴 수 있도록 할 필요가 있다.