Recently, researchers from Cisco and Robust Intelligence conducted jailbreak tests on widely popular AI models. The services evaluated in the study included ▲DeepSeek R1, ▲Meta-Llama 3.1 405B, ▲OpenAI-GPT-4o and o1 (ChatGPT), ▲Google-Gemini 1.5 Pro, and ▲Anthropic-Claude 3.5 Sonnet. The purpose of this test was to assess how effectively each model detects and blocks malicious requests.
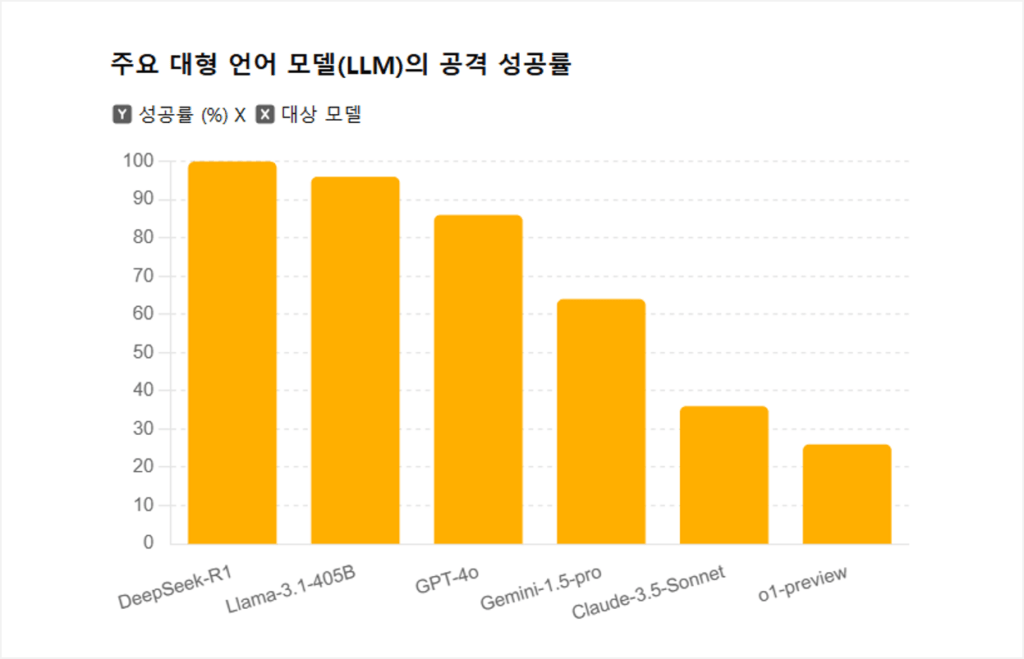
As a result of the test, DeepSeek R1 recorded a 100% attack success rate, allowing all malicious prompts. This was the most vulnerable outcome among the tested models, highlighting the urgent need for DeepSeek AI to strengthen its security. Additionally, the jailbreak success rates of other models were ▲Llama 3.1 405B at 96%, ▲GPT-4o at 86%, ▲Gemini 1.5 Pro at 64%, ▲Claude 3.5 Sonnet at 36%, and ▲GPT-4 o1-preview at 26%, revealing significant differences in security among models. The researchers emphasized that enhancing security mechanisms in AI model development is essential and that continuous testing and improvement are necessary.
This study underscores the importance of security validation to reduce AI models’ susceptibility to cyberattacks and misuse, ensuring they become trustworthy technologies. Given the rapid expansion of generative AI models across various fields, it is crucial to implement technical safeguards to prevent them from generating unauthorized information or providing users with security-compromising outputs.

Such a necessity is also recognized in South Korea, where various verification efforts are underway. In April 2024, the Ministry of Science and ICT conducted a generative AI red team challenge with approximately 1,000 participants to test models from major domestic AI companies. This event focused on identifying risks such as misinformation, bias and discrimination, illegal content generation, AI jailbreaks and cyberattack possibilities, and violations of personal rights in models from Naver, SK Telecom, Upstage, and FortyTwoMaru. Furthermore, on November 26, 2024, the “AI Trust and Safety Conference” was held to share the results of the generative AI red team challenge and discuss policies and scientific strategies for ensuring AI safety.
Additionally, on Friday, February 21, the TTA Academy of the Korea Information and Communication Technology Association will host an AI Safety Seminar. This seminar will introduce the AI Safety Research Institute and its initiatives, as well as provide guidance on AI reliability verification and certification systems. There will also be a session explaining the AI Basic Act and analyzing its impact on the industry, which is expected to help expand understanding of AI reliability and security.
Both globally and domestically, research and verification efforts are actively being pursued to enhance AI security and reliability. These initiatives are expected to contribute to the development of safer and more trustworthy AI technologies. It is essential for us to continuously monitor these evaluation reports, integrate them into our technology selection, and ensure the safe utilization of AI.